Creating the Typology
This library engagement typology divides the public into seven groups of people who have ever used a public library, either in person or online, in addition to two groups of people who have never used a public library. The assignment of individuals to one of the seven core typology groups is based on a two-step analysis comprised of principal components (PCA) analysis to simplify multiple measures of library use, first by identifying and scoring respondents on underlying components of this behavior, and then using PCA scores to run a “cluster analysis” identifying internally consistent groups within the broader universe of library users.
Library Users
The first step in identifying library user “types” involved streamlining a wide array of library use survey questions into core underlying components on which each respondent could be scored. Principal components analysis (PCA) identified seven library use components from a combination of 17 survey questions, many of which were multi-item and used different response scales. To account for variations across question format, PCA was run on a correlation matrix of 25 items from the 17 key survey questions about past and present library use, attitudes toward libraries, and access to library services. The final rotated solution (varimax rotation) identified seven components with Eigenvalues greater than 1, and together these components accounted for 47% of total variance. Component scores were calculated for each respondent for each of these seven components of library use. The combination of library use measures used in the final PCA was determined by running multiple models to see which produced the most consistent and recognizable components, based on measures of fit, face validity, prior Pew Internet research on library use, and extensive qualitative research with library patrons and non-patrons.
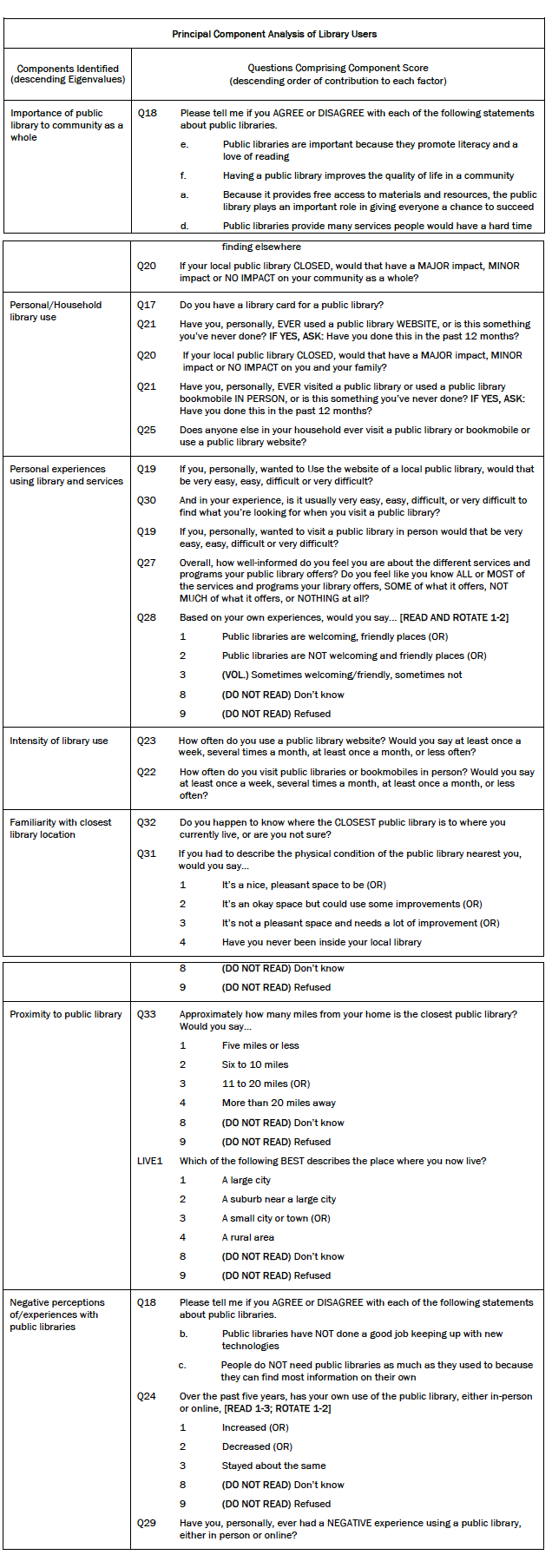
The typology groups were then created using a statistical procedure called “cluster analysis” which uses respondents’ scores on all seven components to sort them into relatively distinct and internally consistent groups. The table below shows each library user group’s mean score on the seven components identified through PCA.
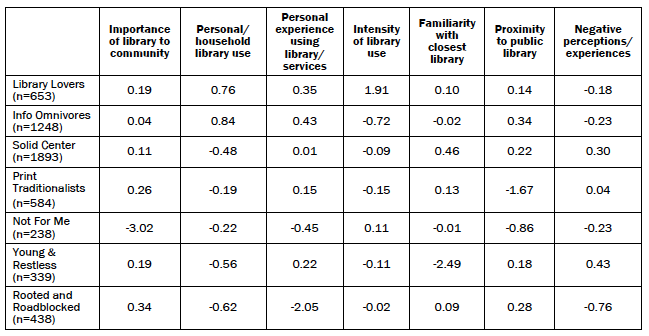
Cluster analysis is not an exact process. Different cluster solutions are possible using the same data depending on model specifications and even the order in which respondents are assessed. Several different cluster solutions were evaluated for their effectiveness in producing cohesive groups that were sufficiently distinct from one another, large enough in size to be analytically practical, and substantively meaningful. While each solution differed somewhat from the others, all of them shared certain key features. The final solution selected to produce the library use typology was judged to be strongest from a statistical point of view, most persuasive from a substantive point of view, and was representative of the general patterns seen across the various cluster solutions.
Library “Non-Users”
Prior to conducting the PCA and cluster analysis, two measures of library use were used to separate library “users” from library “non-users.” Users were defined as anyone who had ever used a public library in the past, either online or in person. Non-users were defined as those who reported never using a public library in either format. Non-users represent 13% of the overall population, and were held aside prior to analysis of library users.
Separating out non-users was critical from both a substantive and statistical standpoint. Substantively, non-users do not have the personal experience necessary to judge the value and performance of public libraries in the same way users can. As a result, they were filtered out of several survey questions that rely on personal experience with libraries. To account for this, a separate analysis was run on non-users using some but not all of the variables included in the user typology. The goal was to determine if there are distinct types of non-users among the broader population of Americans who have no personal experience with public libraries. PCA run on a slightly smaller set of variables (9 rather than 17) identified six underlying components of library experience with Eigenvalues greater than 1, accounting for 62% of total variance. These components are similar to those found in the analysis of library users. The sixth “component” below is comprised of a single variable; for consistency and ease of analysis it was treated as a component and respondents were given a score which could then be used in the cluster analysis with the other five factor scores.
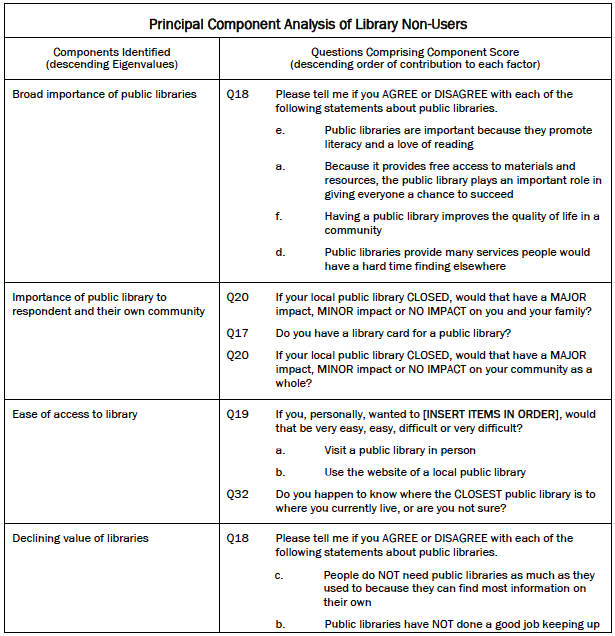

Scores for the six components above were used in a cluster analysis which revealed two fairly distinct groups of “non-users.” The table below shows each library non-user group’s mean score on the six components identified through PCA.

Again, cluster analysis is not an exact process and several different cluster solutions were evaluated for their effectiveness in producing cohesive groups of non-users that were sufficiently distinct from one another, large enough in size to be analytically practical, and substantively meaningful. The final solution selected to produce the library use typology was judged to be strongest from a statistical point of view, most persuasive from a substantive point of view, and was representative of the general patterns seen across the various cluster solutions.
Final Typology Groups
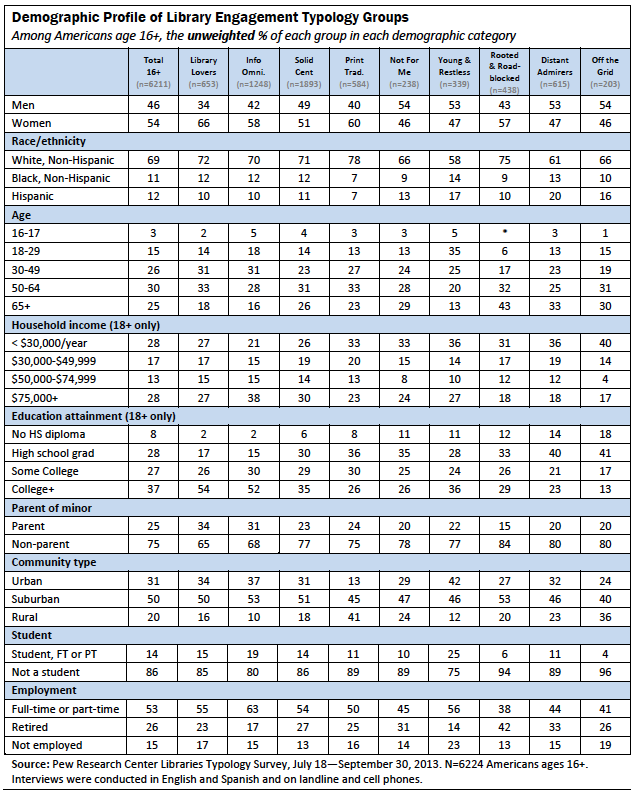
In combination, the above cluster analyses produced a typology of nine separate groups of individuals with fairly distinct and internally cohesive behaviors, perceptions, and attitudes related to public libraries. The table below provides unweighted demographic information for these nine groups. (For a similar table with weighted demographic information, see the Appendix.)
Pew Research Center Library Survey
Prepared by Princeton Survey Research Associates International for the Pew Research Center’s Internet & American Life Project
October 2013
Summary
The Pew Research Center Library Survey, sponsored by the Pew Research Center’s Internet & American Life Project, obtained telephone interviews with a nationally representative sample of 6,224 people ages 16 and older living in the United States. Interviews were conducted via landline (nLL=3,122) and cell phone (nC=3,102, including 1,588 without a landline phone). The survey was conducted by Princeton Survey Research Associates International. The interviews were administered in English and Spanish by Princeton Data Source from July 18 to September 30, 2013.7 Statistical results are weighted to correct known demographic discrepancies. The margin of sampling error for results based on the complete set of weighted data is ±1.4 percentage points. Results based on the 5,320 internet users8 have a margin of sampling error of ±1.5 percentage points.
Details on the design, execution and analysis of the survey are discussed below.
Design and data collection procedures
Sample Design
A combination of landline and cellular random digit dial (RDD) samples was used to represent all adults in the United States who have access to either a landline or cellular telephone. Both samples were provided by Survey Sampling International, LLC (SSI) according to PSRAI specifications.
Numbers for the landline sample were drawn with probabilities in proportion to their share of listed telephone households from active blocks (area code + exchange + two-digit block number) that contained three or more residential directory listings. The cellular sample was not list-assisted, but was drawn through a systematic sampling from dedicated wireless 100-blocks and shared service 100-blocks with no directory-listed landline numbers.
Contact Procedures
Interviews were conducted from July 18 to September 30, 2013. As many as 10 attempts were made to contact every sampled telephone number. Sample was released for interviewing in replicates, which are representative subsamples of the larger sample. Using replicates to control the release of sample ensures that complete call procedures are followed for the entire sample. Calls were staggered over times of day and days of the week to maximize the chance of making contact with potential respondents. Interviewing was spread as evenly as possible across the days in field. Each telephone number was called at least one time during the day in an attempt to complete an interview.
For the landline sample, interviewers asked to speak with the youngest male or female ages 16 or older currently at home based on a random rotation. If no male/female was available, interviewers asked to speak with the youngest person age 16 or older of the other gender. This systematic respondent selection technique has been shown to produce samples that closely mirror the population in terms of age and gender when combined with cell interviewing.
For the cellular sample, interviews were conducted with the person who answered the phone. Interviewers verified that the person was age 16 or older and in a safe place before administering the survey. Cellular respondents were offered a post-paid cash reimbursement for their participation.
Weighting and analysis
Weighting is generally used in survey analysis to compensate for sample designs and patterns of non-response that might bias results. The sample was weighted to match national adult general population parameters. A two-stage weighting procedure was used to weight this dual-frame sample.
The first stage of weighting corrected for different probabilities of selection associated with the number of adults in each household and each respondent’s telephone usage patterns.9 This weighting also adjusts for the overlapping landline and cell sample frames and the relative sizes of each frame and each sample.
The first-stage weight for the ith case can be expressed as:

The second stage of weighting balances sample demographics to population parameters. The sample is balanced to match national population parameters for sex, age, education, race, Hispanic origin, region (U.S. Census definitions), population density, and telephone usage. The Hispanic origin was split out based on nativity; U.S born and non-U.S. born. The White, non-Hispanic subgroup was also balanced on age, education and region.
The basic weighting parameters came from the US Census Bureau’s 2011 American Community Survey data.10 The population density parameter was derived from Census 2010 data. The telephone usage parameter came from an analysis of the July-December 2012 National Health Interview Survey.1112
Weighting was accomplished using Sample Balancing, a special iterative sample weighting program that simultaneously balances the distributions of all variables using a statistical technique called the Deming Algorithm. Weights were trimmed to prevent individual interviews from having too much influence on the final results. The use of these weights in statistical analysis ensures that the demographic characteristics of the sample closely approximate the demographic characteristics of the national population. Table 1 compares weighted and unweighted sample distributions to population parameters.

Effects of Sample Design on Statistical Inference
Post-data collection statistical adjustments require analysis procedures that reflect departures from simple random sampling. PSRAI calculates the effects of these design features so that an appropriate adjustment can be incorporated into tests of statistical significance when using these data. The so-called “design effect” or deff represents the loss in statistical efficiency that results from unequal weights. The total sample design effect for this survey is 1.25.
PSRAI calculates the composite design effect for a sample of size n, with each case having a weight, wi as:

In a wide range of situations, the adjusted standard error of a statistic should be calculated by multiplying the usual formula by the square root of the design effect (√deff ). Thus, the formula for computing the 95% confidence interval around a percentage is:

where p is the sample estimate and n is the unweighted number of sample cases in the group being considered.
The survey’s margin of error is the largest 95% confidence interval for any estimated proportion based on the total sample— the one around 50%. For example, the margin of error for the entire sample is ±1.4 percentage points. This means that in 95 out every 100 samples drawn using the same methodology, estimated proportions based on the entire sample will be no more than 1.4 percentage points away from their true values in the population. It is important to remember that sampling fluctuations are only one possible source of error in a survey estimate. Other sources, such as respondent selection bias, questionnaire wording and reporting inaccuracy, may contribute additional error of greater or lesser magnitude.
Response Rate
Table 2 reports the disposition of all sampled telephone numbers ever dialed from the original telephone number samples. The response rate estimates the fraction of all eligible respondents in the sample that were ultimately interviewed. At PSRAI it is calculated by taking the product of three component rates:13
- Contact rate – the proportion of working numbers where a request for interview was made14
- Cooperation rate – the proportion of contacted numbers where a consent for interview was at least initially obtained, versus those refused
- Completion rate – the proportion of initially cooperating and eligible interviews that were completed
Thus the response rate for the landline sample was 10 percent. The response rate for the cellular sample was 13 percent.







